短链实现
跳转实现原理
浏览器返回302跳转状态码
- 301 永久跳转,浏览器下次不会再访问服务器,而是直接跳转
- 302 临时跳转,浏览器下次还会再返回,便于统计浏览次数等数据统计
短链生成方式
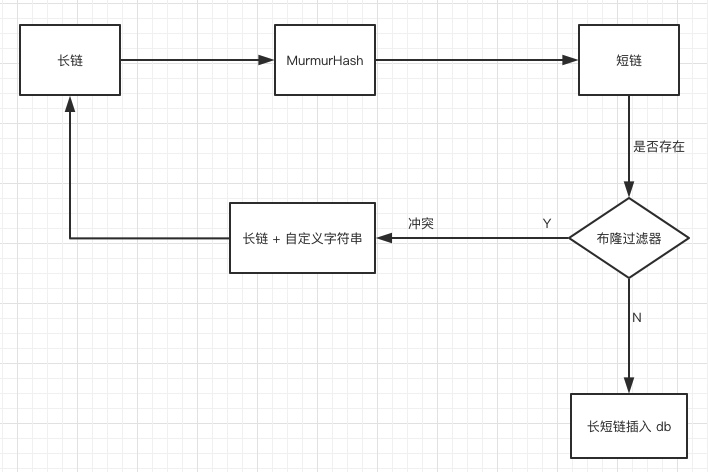
Hash法
url.cn/hash后的原链接
1、对长链做哈希
MurmurHash法
相比于sha、md5等,性能更高,分布更均匀,但相对不安全(个人理解为更容易反推)
2、若哈希得到数字,转化
转化为62进制,进一步缩短长度(24个字母,大小写,加数字)
3、若哈希重复
MySQL存储长短链映射关系,短链做唯一索引,插入时若失败则说明重复
重复时,给长链做转化,如增加特定后缀,再次哈希
4、布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的
实现原理:
对同一个值,生成多个哈希,并记录多个哈希结果
如'baidu',生成 1、4、7
查询时,若1、4、7均有占位,则说明可能存在
若1、4、7有任一一个不存在,则说明一定不存在
自增ID
url.cn/长链id
1、生成自增ID
类UUID,uuid.randomUUid,即机器识别码加uuid,缺点是长且无序,作db主键插入性能低
Redis,10台机器,每台生成以0-9结尾的自增序号,可提高性能。缺点是需要考虑持久化、容灾
雪花算法,机器ID+时间+随机串,缺点是若机器时间回滚有可能重复或乱序
MySQL自增主键
2、MySQL自增主键
如何降低写压力
- 存储记号表,为每台机器提前生成一段范围内的ID
- 机器收到请求后,若在段内,直接返回ID。若不在,则请求再次生成一段ID。
- 机器将ID和长链映射关系保存
- 防止相同长链生成不同ID
- 对长链做md5并存为索引
- 生成时按索引查找
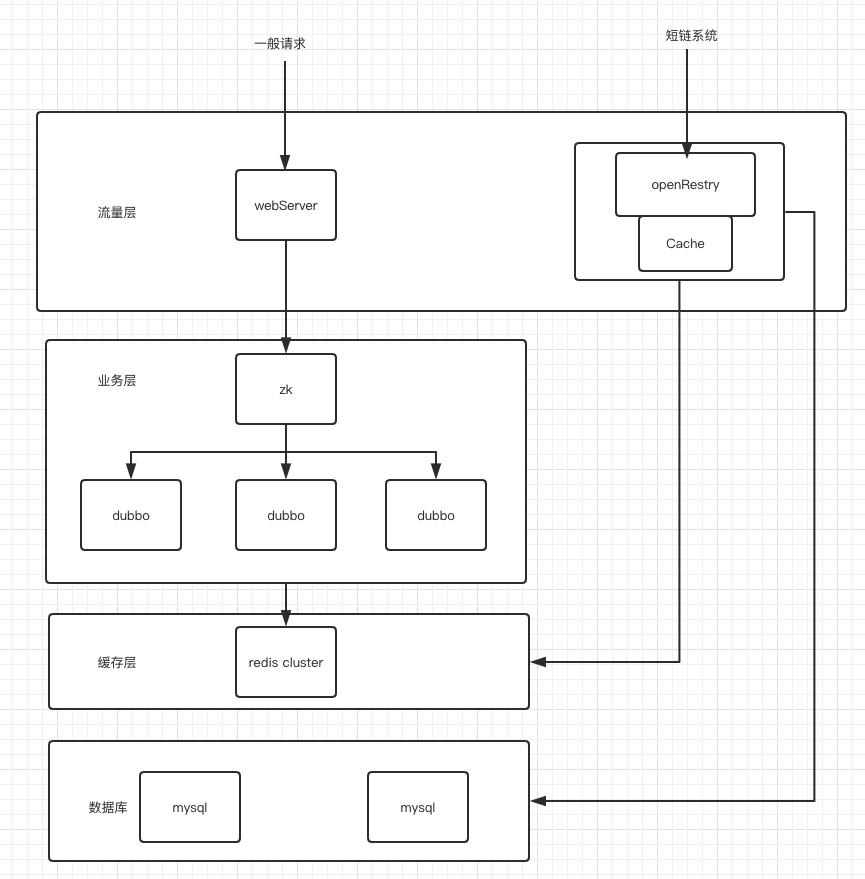
查询系统架构设计
OpenResty
一个 nginx 和 lua 的集成平台,目的是直接在 nginx 内部完成业务逻辑,从而充分利用 nginx 的高并发优势
发布于 2020/09/06
浏览
次